
A Step by Step Guide to Build a Machine Learning Model using SciKit Learn
If you’re a beginner in Machine learning, using scikit-learn is one of the easiest ways to build your own models. While you can also develop your very own models from scratch, it’s not really the smart move since using the built-in functions from the libraries are very convenient and time-saving.
So, in this article, we’ll be going through all the major steps involved while developing a model using scikit-learn and how a dataset is used and processed in such a way that meaningful output can be achieved from it. We’re going to implement a step-by-step coding example covering everything from importing the dataset to evaluating the model's performance.
Ready to build your first Scikit-learn solution? Let’s dive in!
Note: If you prefer video style courses, feel free to watch my Pluralsight course Building Your First Machine Learning Solution.
Agenda
-
Data Source
-
Loading the data
-
Data preprocessing for the Machine Learning Model
-
Data cleaning
-
Feature Selection
-
Building the Machine Learning Model
-
Model Validation
Data Source
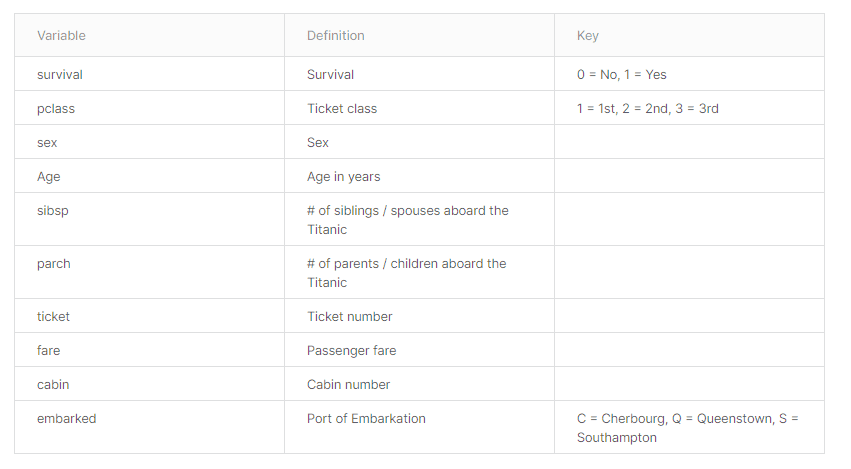
I’ll be using the Titanic dataset, which is available on Kaggle. The goal is to predict whether a person survived or not. This dataset holds the record of each person in the form of 10 variables. The data dictionary can be seen below:
Importing the libraries
First off, we import the basic libraries used for reading the data (the titanic dataset is in the form of a .csv file). The pandas library can be used to read/write csv data in the form of a data frame.
As mentioned before, scikit-learn is a python library for machine learning that focuses on providing a built-in implementation of several techniques. We will be using the following imports for splitting the data, model development, and its validation.


Loading the data
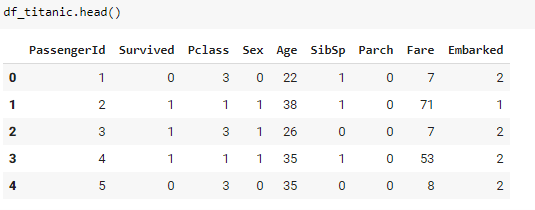
The data is loaded, and the first 5 rows are viewed using pandas. As we can see, there are 10 attributes for each passenger (excluding the Passengerid).

Data Preprocessing for the Machine Learning Model
To use this data for model development, we must first clean the data to make it appropriate for training. Here, the most important step is checking whether the dataset contains any missing values or not.

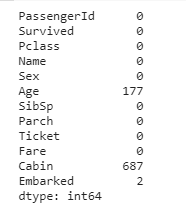
The total number of values for each attribute is 891. As shown, 177 out of those 891 values in the Age column are missing. Similarly, there are 687 missing values in the Cabin column. Moreover, 2 values are missing for the Embarked attribute. In this way, an idea about the data is made.
Data Cleaning
The Name and Ticket attributes are unique for each passenger, which plays a role in data prediction. So, we remove this feature from our dataset.

As seen, the Cabin attribute has approximately 77% of missing data. In such a case, data imputation is not proper, so we will remove this feature.

Now, to fill the rest of the missing values, we start with Age. Since it only has 177 missing values, we will use the mean age to fill those values.

There are 2 missing values in the Embarked feature, which are replaced by the most common value 'S'.

After this, the cleaned data can be observed as follows.
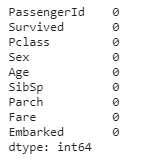
Our transformed dataset after cleaning becomes
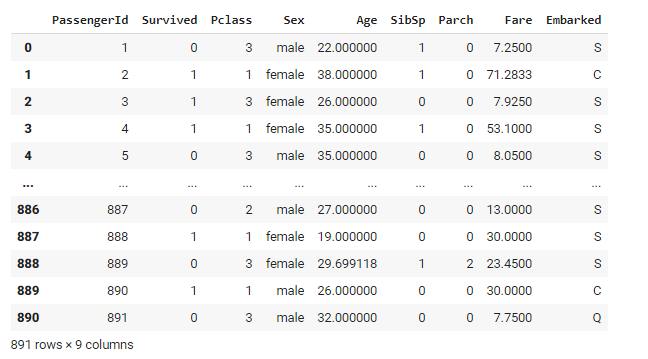
The cleaned attributes Age and Class are termed as numerical attributes while the Pclass, Sex, SibSp, Parch, and Embarked are categorical attributes.

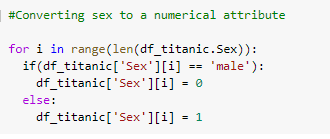
Moving further, we observe that the data is consistent as Sex and Embarked exist as strings. These features are converted to numerical data (Male -> 0, Female -> 1 for Sex and 0-> S, C -> 1, Q -> 2 for Embarked).

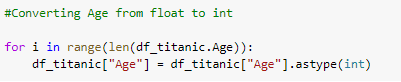
Age and Fare exist as a float, so they are converted to int to have consistent data types all across the dataset.

The transformed dataset can now be seen as:
Feature Selection
The Survived attribute is selected as the target class that is to be predicted, which indicated whether a person survived or not. The rest of the attributes (PassengerId, Pclass, Sex, Age, SibSp, Parch, Fare, Embarked) are regarded as the predicting attributes. The features and target class are respectively stored as X and y.


Test Train Split
The data is split into a train and test class so that model evaluation can be performed fairly since the data used for testing is not already seen and hence ‘learned’ by the algorithm. So, the cleaned dataset is now divided into a test and train split. This can be done by using sklearn built-in method. A 75-25 split is done, and the respective data is stored as X_train, X_test, y_train, y_test.

Building the Machine Learning Model
A Linear Regression model is used for training the data. A built-in function can be used from scikit-learn to perform this. Linear Regression attempts to build a model between variables by passing a linear line between them to predict the output for data that is currently not visible with the belief that it may fall on the same line or within its proximity. It is termed as simple linear regression for one explanatory variable, while for more than variables, it is termed as multiple linear regression.
The .fit() method of the linear regression model fits the regression line across the training features, X_train, and y_train.

Model Validation
The next step is predicting the results for the test attributes. This can be done using the .predict() function of the built-in Linear Regression model, which was trained in the last step, one of the test data that we set aside earlier.

The model predicts the values between the two classes 0 (did not survive) and 1 (survived) for all the passengers. This is done by plotting a line that best fits the data points.
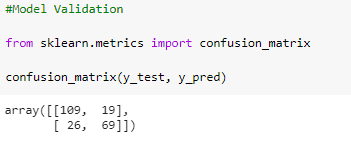
After this, a confusion matrix can be formed to see the result of all the predictions. This is done by mapping the predicted output with the original output from the test data.
Conclusion
Linear regression model is a very basic and intuitive machine learning algorithm that is easy to understand and quite straightforward to use. Moreover, the libraries like scikit-learn make it further easy for us to implement and evaluate such algorithms and subsequently making your own machine learning solutions.
Throughout the article, we have covered all the major steps included in making a machine learning model. I hope the article will help you grasp the major concepts and help you form your basics.
If these steps seem to be so expansive, feel free to read AI as a Service to learn how to build machine learning solutions easily.