
Sentiment Analysis Tools: Guide to Call Center Performance -1
Background
Objective measurement of unstructured data such as video, text, and audio has always been a challenge for BI, which is primarily focused on structured data, big data analytics aims to bridge this gap by its ability to analyze unstructured data. This is closely related to what we are going to do in today’s tutorial using AI services.
Daily, we deal with different organizations, companies and service firms that provide call centers endpoint such telephone numbers, email addresses, and emails. How happy and satisfied are we is a critical metric for the end firm stakeholders, as our impressions and perceptions will have a direct influence on the firm’s reputation and figures. Therefore, it is of primary importance for the firm to be able to objectively and efficiently measure and assess their customer service endpoints and appraise its performance and continuously improve it.
Problem Statement
The objective of this tutorial is to analyze a customer call scenario and assess it objectively, possibly in form of reports. To achieve the objective, we need to perform the following steps:
- Transcribe the call content to text.
- Apply sentiment analysis to the extracted text and obtain measures.
Figure 1 illustrates a simplified architecture for our solution.
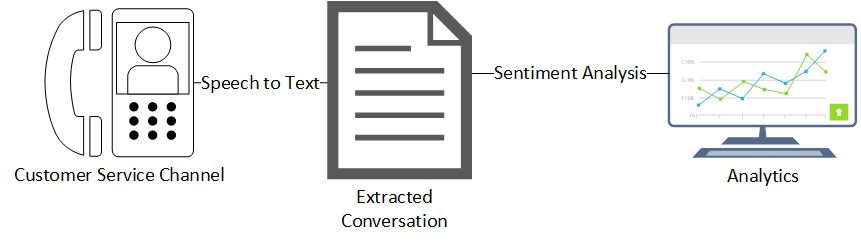
Technology selection
As I we discussed previously in (Democratized AI – AI as a Service for all!) there are plenty of technology choices for the cognitive APIs that require research and analysis. Firstly, let us explore some of the options for our solution in detail and develop more understanding of the capabilities of each service.
Speech to text
Intuitively speaking, speech to text is the process of converting speech to transcribed text. Even though it looks simple on the surface, there are lots of subtle details the developer has to carefully consider before opting to a particular vendor. I will discuss briefly the most important ones.
Supported languages: Speech to text R&D is not progressing equally in all languages, some languages, such as English, are highly supported among vendors. Other languages such as Arabic is partly supported, while some languages are almost not supported. You must carefully analyze your business domain and use case to determine the most suitable option. Currently, Google has the most extensive language support with more than 120 supported language.
Timestamps: Some APIs generate timestamps on the transcription, make it easy for you to identify the particular moment a specific word/thing has been mentioned. This is useful in scenarios where you need to audit or verify something.
Language detection: If you have a multinational call center, the language detection feature could be valuable for you, by making the transcription process automation easier and removing required human intervention to sort out languages.
Custom vocabulary: Some domains, such as IT and medicine has very specific terminologies and abbreviations that make it challenging for traditional speech to text services to detect. Therefore, custom vocabulary allows the speech to text service to be taught particular specific phrases to increase its recognition ability in highly domain-specific environments.
Speaker identification: Also called (diarization) allows labeling and attributing speakers in multi-speaker environments (e.g., meetings).
Channel identification: Allows separation of transcription based on the emitting channel (e.g., phone calls, conference meeting, etc.).
Streaming: Streaming allows semi-real time speech to text using TCP based WebSocket technology, which consumes less bandwidth and has lower latency.
Pricing: Pricing typically differs among services based on usage tiers and capping limits, there is no apple to apple comparison here, as not all vendors have similar features. You need to dig more to understand the exact pricing based on your scenario and expected usage.
There are other qualities that worth considering during comparison such as punctuation support, inappropriate content filtering, noise cancellation, supported file formats, sampling rates and how the service responds on hesitation (e.g. failure to identify particular word). Table 1 provides a summary of capabilities of different players in the market. Kindly note that updates and changes are very frequent, you need to consult their respective official website for the latest status.
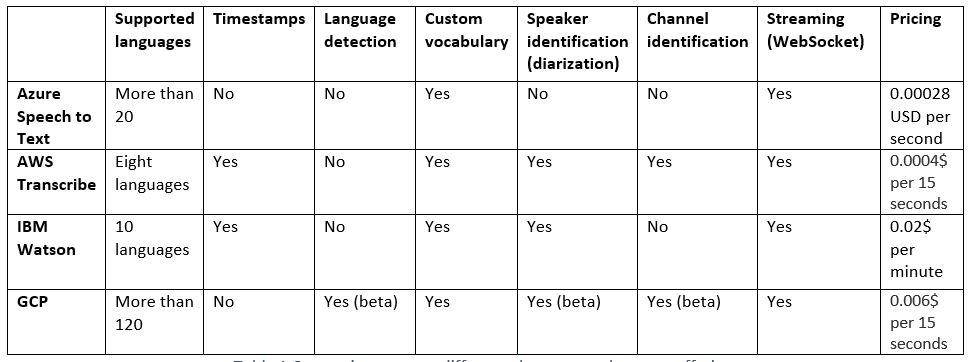
In our tutorial we will opt to use GCP Speech to Text service, there is no particular reason behind this choice except playing with new APIS.
That is it for now, and stay tuned for part 2 soon where will discuss sentiment analysis : - )